
The following paper recently came to my attention:
Varnum MEW, Krems JA, Morris C, Wormley A, Grossmann I (2021) Why are song lyrics becoming simpler? a time series analysis of lyrical complexity in six decades of American popular music. PLoS ONE 16(1): e0244576. doi:10.1371/journal.pone.0244576
It attempts to analyze lyrical complexity of top 100 songs and correlate it to their success, socio-economical factors, and so on. I am not really qualified to talk about most of the work they are doing (they all are from psychology departments and talk about what probably are psychology things), but as an ex-computer science student, current multimedia production student and a hobbyist writer, I do feel qualified to talk about this line in their methodology specifically:
Compressibility indexes the degree to which song’s lyrics have more repetitive and less information dense, and thus simpler, content. We used a variant of the established LZ77 compression algorithm.
LZ77 is an ancient compression algorithm from 1977 (hence the name). It’s the granddad of the modern deflate algorithm used to compress webpages, PNGs, ZIPs, PDFs, ODTs, DOCXs, and so on. The authors correctly identify:
We used the LZ77 compression algorithm because of its intimate connection to textual repetition. Most of the byte savings when compressing song lyrics arise from large, multi-line sections (most importantly the chorus, and chorus-like hooks).
The words “byte savings” already is hinting at what the problem here might be. Because, yes, if your lyrics repeat the same thing over and over again (and to be fair, pop songs often do), and if you ZIP it up, it will take up less space on your disk and yes, in information theory, the song would be less complex.
But we as listeners aren’t really interested in information theory and degrees of compression. If anything, we might be interested in whether the lyrics go for a very simple rhyme, or a combo that’s been heard hundreds of times before (house → mouse, fire → desire, heart → apart, etc – rhymezone is very useful to find common pairings), or for one you don’t see coming (eg. Madvillain’s Meatgrinder “trouble with the script → subtle lisp midget”). The ZIP algorithm won’t be able to tell the complexity of the rhymes apart, it only can judge whether or not words or phrases are literally repeating.
And even that isn’t necessarily a good metric to judge complexity. Take the lyrics of Rammstein’s Du hast for example:
Du
Du hast
Du hast mich
Du hast mich
Du hast mich gefragt
Du hast mich gefragt
Du hast mich gefragt und ich hab’ nichts gesagt
This is some ZIP-tastic lyrics and proof that these lyrics are simple – except they aren’t. This is a wordplay on “du hast” (you have) and “du hasst” (you hate). If you hear these lyrics, you’re constantly trying to decypher which of the two meanings this hast/hasst they’re talking about, and the four (!) “Du / du hast / du hast mich” repititions before the song even gets to the verse quoted above make it a very cognitively engaging, and, dare I say, complex song up to that point, just by repeating an unclear phrase.
So, we have established that any conclusions drawn from ZIP-ping up song lyrics are shaky at best, I have another question:
Why, why, why a ZIP algorithm?
It is beyond me why the first thing you’d head to when tasked “measure whether new songs are simpler” is LZ77, or any kind of compression algorithm. Compression algorithms will look at substrings, so h[ouse] and m[ouse] would be better to compress as a pair than ho[use] and ca[use], because the repeated substring is longer. But house, mouse, cause are all just 5-letter-words which (vaguely) rhyme, so there’s no reason to count one pairing more or less complex than the other.
And it’s not like there aren’t metrics which are designed to look at this problem in particular: Lexical Diversity Indices exist, here’s a paper describing all their differences, doi:10.3758/BRM.42.2.381. And even that paper admits:
In sum, all textual analyses are fraught with difficulty and disagreement, and LD is no exception. There is no agreement in the field as to the form of processing (sequential or nonsequential) or the composition of lexical terms (e.g., words, lemmas, bigrams, etc.) […] In this study, we do not attempt to remedy these issues. Instead, we argue that the field is sufficiently young to be still in need of exploring its potential to inform substantially.
So even when analyzing with an algorithm designed to measure lexical diversity, it still would run into trouble, especially when being ran in the “full auto” mode that is necessary to classify tens of thousands of texts.
The research already has been done
Varnum et al. fail to acknowledge the research of Isaac Piraino, published at least a year prior to theirs. Piraino took 450k song lyrics (as opposed to Varnum et al.’s 15k), filtered to only include lyrics above 100 words (because short lyrics necessarily are more diverse; you first need to write a word before you can repeat it), and measured them with MTLD (a metric actually designed to measure lexical diversity).
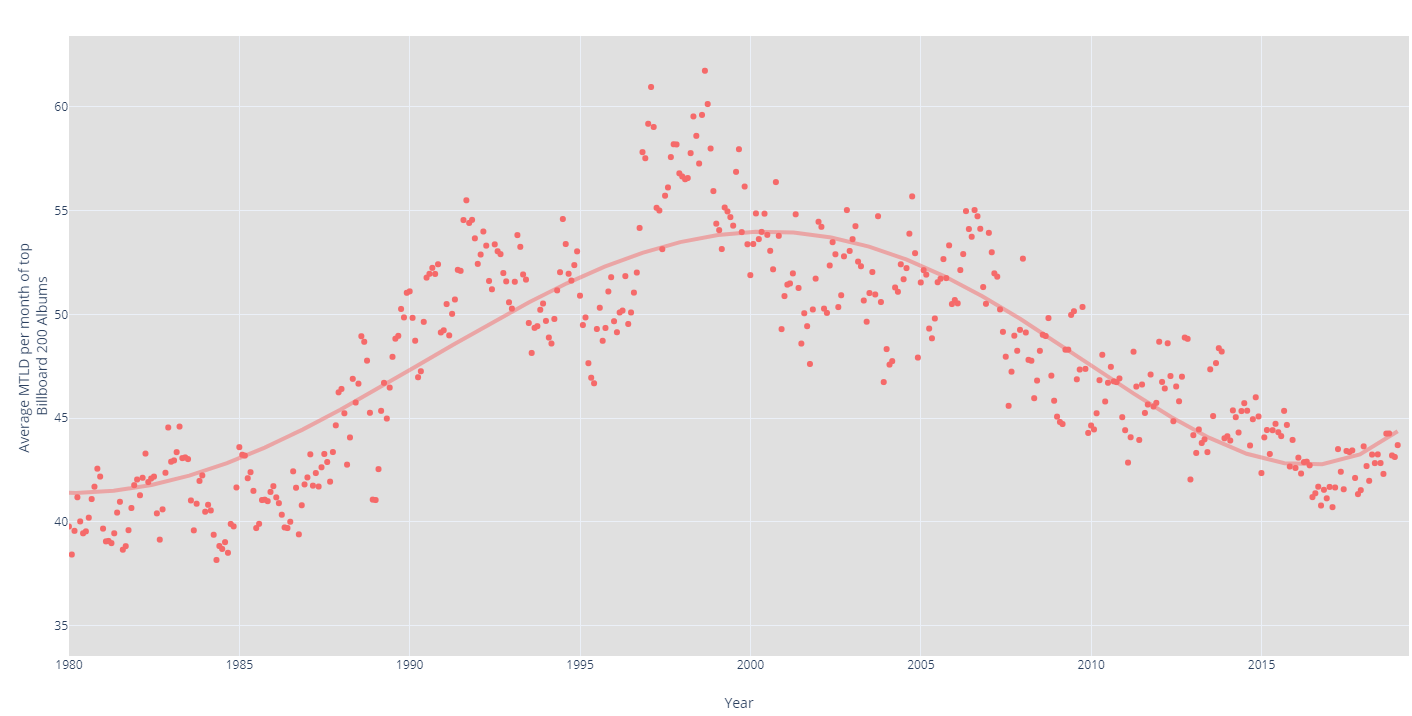

Piraino hypothesizes:
My theory is that the gradual decrease in the popularity of rock music and increase in popularity of hip-hop explains the upward trend to the end of the 90s. Rock music, although complex in different ways, usually has a more simple vocuabulary than its lyrically dense hip-hop counterpart. My theory for why it went back down after the 90s is that hip-hop has slowly been transforming into pop music in combination with the rise in popularity of EDM. […] EDM typically has a handful of catchphrases that are repeated over and over again.
Conclusion
Varnum et al. acknowledge that “Songs might be complex or simple in other ways as well, in terms of rhythm, melody, number of instruments played, and so on.” But since their methodology is so shaky, and their results seem to contradict other research, I’d be very, very careful to even try to draw any conclusions from this. Or really, most things which try to algorithm away at huge datasets and then try to explain the most intricate and inter-connected thing humanity has to offer, culture, with it. Overall, it reminds me of the “timbre paper” floating around, which tries to measure musical quality by how much timbre it has (and got torn apart over it):
